

Technical
Categorization module


-
The Language Processing Framework
-
ATLAS system database
-
Overview
-
ATLAS core database
-
Common language processing tools
-
MT Overview
-
Overview
-
Overview
-
Atlas Overview
-
Bulgarian LPC
-
Categorization algorithms
-
English LPC
-
Export and import
-
File storage
-
German LPC
-
Greek LPC
-
i-Librarian
-
Installation and configuration of an ATLAS component
-
MT in Atlas
-
Overview, properties and relations
-
Pages
-
Polish LPC
-
Purpose of the document
-
Romanian LPC
-
Servlets and Filters
-
Summary Overview
-
System chapter
-
System layers
-
Approval
-
Categorization module
-
Common concepts
-
Content model
-
EUDocLib
-
Handling the HTTP request
-
Key features
-
Pre-required software
-
Scope of the document
-
Summary Module
-
Text mining relational data
-
Widgets
-
Aliases
-
ATLAS components
-
Categorisation and data mining
-
Component plugins
-
Diagrams
-
Intended audience of the document
-
Renderers
-
Text mining extracts visualization
-
Text mining Lucene storage
-
Users, groups and access rights
-
Datasources and selections
-
Document structure
-
History and revisions
-
Navigations
-
Plugin communication and request processing
-
Stubs
-
About ATLAS
-
Approval chains
-
Sitemap
-
Cache
-
Themes
-
Access Log
-
Site Seach
-
Site users
-
CLIR Overview
-
CLIR processes outline
-
Integration of CLIR in Atlas
Overview
ATLAS has a module for automatic categorization of documents, which provides access to several statistical and distance based algorithms. The categorization module instantiates the configured algorithms with different feature types; furthermore, the module is able to start several algorithms simultaneously and combine the results of each classifier.
Implementation
The module registers one or more algorithms as OSGI services, according to the configuration settings. ATLAS uses these services for categorization tasks which users initiate.
The plugin com.tetracom.atlas.textmining.categorization.algorithms contains implementations of the different categorization algorithms available in ATLAS.
The file com.tetracom.atlas.textmining.categorization.algorithms.properties contains the configuration settings for the automatic categorization module. The file has the following format:
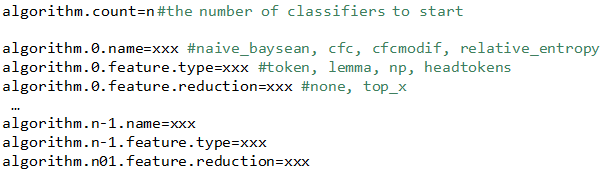
The class CategorizationAlgorithmsProviderService reads the configuration settings, creates instances of the categorization algorithms, and registers them as OSGI services.
Each categorization algorithm is an instance of the ISpecificAutomaticCategorizationService interface. CategorizationAlgorithmFactory uses three parameters to create ISpecificAutomaticCategorizationService instances - name, feature.type and feature.reduction.
Possible options for the name parameter are:
- naive_bayesian (Naïve Bayesian Algorithm).
- relative_entropy (Relative Entropy Algorithm)
- cfc (Class-Featured Centroid Algorithm)
- cfcmodif (Modifed Class-Featured Centroid Algorithm)
Possible options for the feature.type parameter are:
- token (Features based on tokens)
- lemma (Features based on lemmas)
- np (Features based on noun phrases)
- headtokens (Features based on head tokens)
Possible options for the feature.reduction parameter are:
- none (Feature reductions is not applied)
- top_x (where x is a number between 1 and 100 – the percentage of features to keep)
Bases on these parameters, CategorizationAlgorithmFactory returns a new CategorizationAlgorithm object, which is constructed with corresponding IFeatureSpaceReducer, ICategoryVectorCreator and IDocsClassifier instances.
Each ISpecificAutomaticCategorizationService generates its own algorithm identifiers of the form algorithmIdentifier = name _ feature.type _ feature.reduction.
This identifier is used to distinguish between different instances of the algorithms in the application.
The following sequence of actions is executed in the CategorizationAlgorithm.createModel method:
- Document features (according to the feature.type parameter) for all of the training documents are fetched from the data store.
- The feature space for the training set is built.
- The feature space is reduced by the IFeatureSpaceReducer.
- The training document features are normalized.
- ICategoryVectorCreator creates the categories vectors.
- The Category vectors are normalized.
- A new instance of BinaryModel is returned as a result.
The following actions are executed in the CategorizationAlgorithm.useModel method:
- Document features (according to the feature.type parameter) for all of the unlabeled documents (test documents) are fetched from the data store.
- All test documents that do not have features from the model space are ignored.
- The test document features are normalized.
- IDocsClassifier classifies the documents.
- The classification results are returned as Map< UUID/*doc uid*/, Map< UUID/*cat uid*/, Double/*relevance*/ >>.
; return false;") |
ATLAS (Applied Technology for Language-Aided CMS) is a project funded by the European Commission under the CIP ICT Policy Support Programme.